Regresja logistyczna często pojawia się wtedy, gdy w pracy dyplomowej nie analizujesz zwykłego wyniku liczbowego, tylko odpowiedź typu 0/1. Może chodzić o to, czy ktoś należy do danej grupy, czy wystąpiło dane zachowanie, czy pacjent spełnia określone kryterium, czy badany odpowiedział „tak” albo „nie”. I tu zaczyna się temat: regresja logistyczna interpretacja. Bo sam wynik z programu wygląda poważnie, ale bez zrozumienia odds ratio, p-value i kierunku zależności bardzo łatwo napisać coś, co brzmi statystycznie, ale nie mówi zbyt wiele.
Czym jest regresja logistyczna i kiedy ma sens
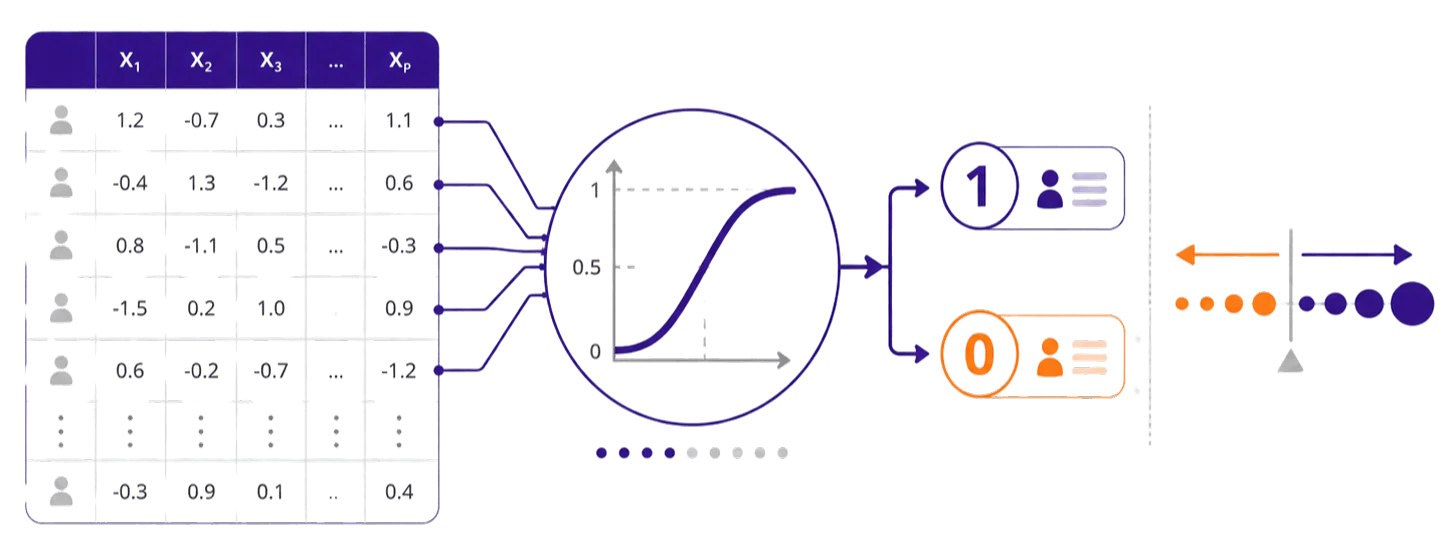
Regresja logistyczna ma sens wtedy, gdy zmienna zależna ma charakter binarny, czyli przyjmuje dwie kategorie. Najczęściej zapisuje się ją jako 0 i 1, na przykład: brak objawu / obecność objawu, nie / tak, brak sukcesu / sukces, niekorzysta / korzysta. To odróżnia ją od klasycznej regresji liniowej, która zakłada wynik liczbowy, ciągły i możliwy do opisania prostą linią.
W praktyce regresja logistyczna w pracy magisterskiej przydaje się wtedy, gdy chcesz sprawdzić, czy konkretne zmienne zwiększają albo zmniejszają szansę wystąpienia danego wyniku. Możesz na przykład badać, czy wiek, poziom stresu i wsparcie społeczne przewidują prawdopodobieństwo wypalenia zawodowego. Albo czy określone cechy ankietowanych wiążą się z decyzją „tak/nie”. Jeżeli dopiero zastanawiasz się, czy w Twoim przypadku lepsza będzie korelacja, regresja liniowa czy model logistyczny, zacznij od wpisu jak dobrać test statystyczny do pracy dyplomowej.
Regresja logistyczna nie odpowiada więc na pytanie „o ile średnio wzrośnie wynik Y”, tylko raczej: „czy i jak dana zmienna wpływa na szanse wystąpienia wyniku 1”. To subtelna, ale bardzo ważna różnica. I właśnie dlatego nie warto opisywać jej tak samo jak regresji liniowej. Jeśli pracujesz na wyniku liczbowym, pomocny będzie osobny wpis regresja liniowa w pracy magisterskiej.
Regresja logistyczna interpretacja – co oznacza wynik 0/1
W modelu logistycznym najważniejsze jest to, jak zdefiniujesz kategorię 1. To ona jest zwykle traktowana jako zdarzenie, którego wystąpienie próbujesz przewidzieć. Jeśli 1 oznacza „wystąpiło wypalenie”, model będzie dotyczył szansy wystąpienia wypalenia. Jeśli 1 oznacza „brak wypalenia”, interpretacja pójdzie w drugą stronę. Niby detal, ale taki detal potrafi zrobić z interpretacji piękny statystyczny naleśnik przyklejony do sufitu.
Dlatego przed analizą trzeba jasno ustalić, co oznacza 0, a co oznacza 1. Bez tego bardzo łatwo napisać odwrotny wniosek: że dana zmienna zwiększa szansę wystąpienia zjawiska, podczas gdy tak naprawdę zwiększa szansę jego braku. W pracy dyplomowej warto opisać to wprost, zwłaszcza jeśli zmienna zależna nie jest intuicyjna. Krótkie zdanie typu „w modelu wartość 1 oznaczała wystąpienie analizowanego zjawiska” potrafi uratować całą interpretację.
Właśnie dlatego zmienna zależna 0/1 nie jest tylko technicznym zapisem w arkuszu. To fundament interpretacji. Jeżeli źle ustawisz kodowanie, program nadal policzy wynik, ale Ty możesz opisać go w przeciwnym kierunku. Statystyka bywa bezlitosna: program zrobi dokładnie to, o co prosisz, nawet jeśli prosisz go o coś, czego nie miałeś na myśli.
Co oznacza odds ratio w regresji logistycznej
Najczęściej interpretowanym elementem regresji logistycznej jest odds ratio w regresji logistycznej, czyli iloraz szans. W dużym uproszczeniu pokazuje on, jak zmieniają się szanse wystąpienia wyniku 1 przy zmianie predyktora. UCLA OARC o interpretacji odds ratio dobrze pokazuje, że współczynniki regresji logistycznej są trudniejsze do bezpośredniego czytania niż w regresji liniowej, dlatego często przechodzi się właśnie na odds ratio.
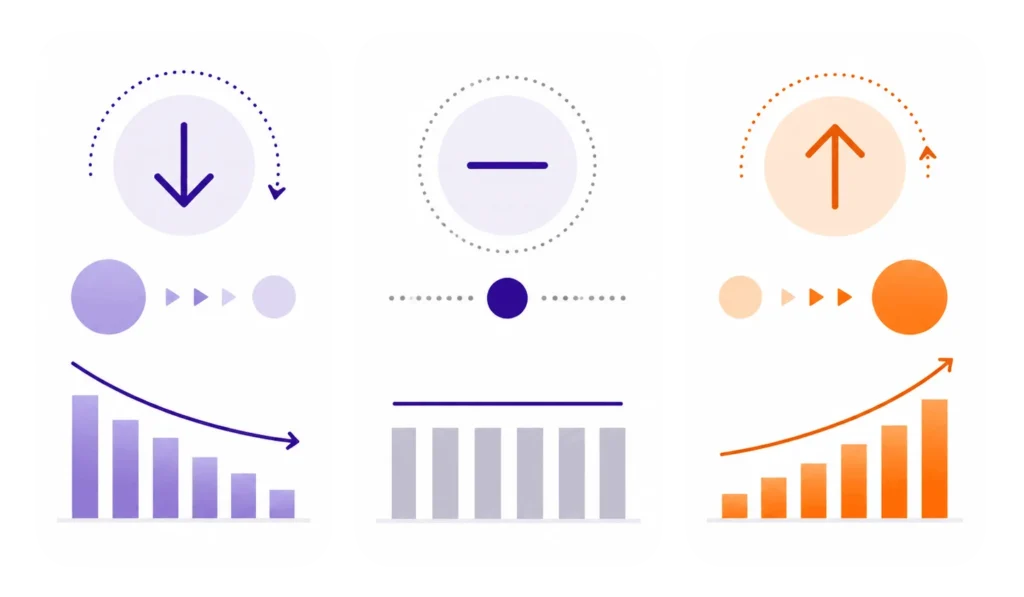
Jeśli odds ratio wynosi 1, oznacza to brak zmiany szans. Jeśli jest większe niż 1, szanse wystąpienia zdarzenia rosną. Jeśli jest mniejsze niż 1, szanse maleją. Brzmi prosto, ale trzeba uważać na język. Odds ratio nie oznacza automatycznie „procentowego wzrostu prawdopodobieństwa”. To częsty błąd. Mówimy o szansach, nie bezpośrednio o prawdopodobieństwie.
Odds ratio większe, mniejsze i równe 1
Przykład: jeśli odds ratio dla zmiennej „wysoki poziom stresu” wynosi 2,00, można powiedzieć, że osoby z wysokim poziomem stresu mają dwukrotnie wyższe szanse wystąpienia analizowanego wyniku niż osoby z grupy odniesienia, przy założeniu tego konkretnego modelu. Jeśli odds ratio wynosi 0,50, szanse są o połowę niższe. Jeśli wynosi 1,00, predyktor nie zmienia szans wystąpienia wyniku.
Przy zmiennych ilościowych interpretacja dotyczy zwykle wzrostu predyktora o jedną jednostkę. Jeśli na przykład odds ratio dla wieku wynosi 1,08, można powiedzieć, że wraz ze wzrostem wieku o jedną jednostkę szanse wystąpienia wyniku 1 rosną 1,08 razy. Penn State o regresji logistycznej i odds ratio pokazuje podobną logikę: odds ratio większe niż 1 oznacza wyższe szanse zdarzenia, a mniejsze niż 1 – niższe szanse.
To jest właśnie moment, w którym iloraz szans interpretacja musi być precyzyjna. Nie wystarczy napisać „wynik jest istotny”. Trzeba jeszcze wskazać, czy predyktor zwiększa, czy zmniejsza szanse wyniku, jak silny jest ten efekt i czego dokładnie dotyczy kategoria 1.
Jak czytać p-value, przedział ufności i dopasowanie modelu
W regresji logistycznej p-value pokazuje, czy dany predyktor jest statystycznie istotny w modelu. Nie mówi jednak samo z siebie, czy efekt jest duży, sensowny albo praktycznie ważny. Dlatego warto czytać je razem z odds ratio i przedziałem ufności. Jeżeli p-value jest istotne, ale odds ratio jest bardzo blisko 1, efekt może być statystycznie wykrywalny, ale niezbyt mocny interpretacyjnie.
Przedział ufności pomaga ocenić precyzję oszacowania. Jeśli przedział ufności dla odds ratio jest bardzo szeroki, wynik jest mniej stabilny i wymaga ostrożniejszego komentarza. Jeżeli przedział obejmuje wartość 1, często oznacza to brak jednoznacznego efektu przy przyjętym poziomie ufności. Warto więc patrzeć nie tylko na jedną liczbę, ale na cały zestaw informacji: OR, p-value i przedział ufności.
Do tego dochodzi ocena dopasowania modelu. W zależności od programu możesz spotkać pseudo R², test Hosmera-Lemeshowa, klasyfikację przypadków albo inne wskaźniki. Nie każdy z nich trzeba opisywać szczegółowo w prostej pracy dyplomowej, ale warto wiedzieć, że regresja logistyczna to nie tylko tabela z predyktorami. Jeśli masz już output z programu, ale nie wiesz, które liczby naprawdę powinny trafić do rozdziału wyników, pomocny będzie też wpis jak opisać wyniki statystyczne w pracy dyplomowej krok po kroku.
Najczęstsze błędy przy interpretacji regresji logistycznej
Najczęstszy błąd to mylenie odds ratio z prawdopodobieństwem. Jeśli OR wynosi 2,00, nie oznacza to automatycznie, że prawdopodobieństwo wzrosło o 200% albo że badany ma 200% szans na wynik. Oznacza to zmianę szans, a to nie jest dokładnie to samo. Taki błąd wygląda niewinnie, ale w pracy dyplomowej może mocno zepsuć interpretację.
Drugi błąd to ignorowanie kodowania zmiennej zależnej. Jeśli nie wiadomo, co oznacza 1, cała interpretacja stoi na bardzo kruchym fundamencie. Trzeci błąd to opisywanie każdego predyktora osobno bez spojrzenia na cały model. W regresji logistycznej ważne jest to, że predyktory są analizowane razem, więc interpretacja dotyczy efektu danego predyktora przy kontroli pozostałych zmiennych w modelu.
Czwarty błąd to wrzucanie do modelu zbyt wielu zmiennych „bo są w bazie”. Model nie jest śmietnikiem na wszystkie kolumny z Excela. Predyktory powinny wynikać z hipotez, teorii albo sensownego planu analizy. Jeżeli dane są jeszcze nieuporządkowane, zacznij od wpisu jak oczyścić dane do analizy statystycznej, bo regresja na brudnych danych to trochę jak budowanie domu na budyniu. Da się zacząć, ale finał będzie miękki.
Jak opisać regresję logistyczną w pracy dyplomowej
Dobry opis regresji logistycznej powinien najpierw wyjaśnić, co było zmienną zależną i jak została zakodowana. Następnie warto wskazać, jakie predyktory wprowadzono do modelu. Dopiero potem przechodzisz do wyniku: które predyktory okazały się istotne, jakie było odds ratio, jaki był kierunek zależności i co to oznacza w kontekście pytania badawczego.
Przykład prostego opisu może wyglądać tak:
„W celu sprawdzenia, czy poziom stresu i wsparcie społeczne przewidują wystąpienie wypalenia zawodowego, przeprowadzono regresję logistyczną. Zmienna zależna została zakodowana jako 0 = brak wypalenia, 1 = wystąpienie wypalenia. Wynik wskazał, że wyższy poziom stresu istotnie zwiększał szanse wystąpienia wypalenia, OR = 2,15; p = 0,012. Oznacza to, że wraz ze wzrostem poziomu stresu rosły szanse zaklasyfikowania osoby do grupy z wypaleniem.”
Taki opis jest lepszy niż samo przepisanie tabeli z programu. Pokazuje, co analizowano, jak zakodowano wynik, który predyktor był istotny i jak rozumieć kierunek efektu. W pracy dyplomowej chodzi właśnie o to: nie tylko policzyć model, ale jeszcze przełożyć go na sensowny, czytelny język.
Kiedy warto skonsultować wynik regresji logistycznej
Warto skonsultować wynik wtedy, gdy masz tabelę z regresji logistycznej, ale nie masz pewności, co oznaczają poszczególne kolumny. Szczególnie jeśli pojawiają się tam B, Exp(B), Wald, p-value, przedziały ufności i kilka predyktorów naraz. To nie jest moment na zgadywanie, bo jeden źle opisany kierunek może zmienić cały wniosek z analizy.
Konsultacja ma sens także wtedy, gdy nie wiesz, czy regresja logistyczna w ogóle pasuje do Twojego pytania badawczego. Czasem lepszy będzie test chi-kwadrat, czasem regresja liniowa, a czasem właśnie model logistyczny. Jeśli chcesz uporządkować analizę od wyboru metody aż po opis wyniku, zobacz usługę analizy statystycznej albo przejdź do kontaktu i podeślij układ badania do wstępnej oceny.
Jeśli masz wynik 0/1 i nie chcesz opisywać regresji logistycznej na wyczucie, mogę pomóc sprawdzić model, zinterpretować odds ratio i przygotować opis wyników do pracy dyplomowej. Dzięki temu zamiast walczyć z tabelą pełną skrótów, dostajesz jasny opis: co wyszło, co to oznacza i jak napisać to tak, żeby miało sens metodologiczny.





