W wielu pracach dyplomowych analiza statystyczna kończy się na prostym pytaniu: „czy wyszło istotnie?”. To zrozumiałe, bo p-value jest najczęściej pierwszą liczbą, na którą patrzy autor pracy, promotor i czasem recenzent. Problem w tym, że samo p-value nie mówi jeszcze, jak duże jest zjawisko, jak precyzyjny jest wynik i czy ma ono sens praktyczny. Dlatego coraz ważniejsze staje się raportowanie czegoś więcej: effect size i przedziały ufności. To one pomagają przejść od suchego „wyszło / nie wyszło” do rzeczywistej interpretacji wyniku.
Dlaczego samo p-value nie wystarczy do dobrej interpretacji
P-value informuje, czy przy przyjętym poziomie istotności wynik można uznać za statystycznie istotny. Nie mówi jednak, czy różnica była mała, średnia, duża ani czy wynik ma realne znaczenie w kontekście badania. To trochę tak, jakby powiedzieć: „coś się wydarzyło”, ale bez informacji, czy była to lekka mżawka, czy powódź w piwnicy. Niby informacja jest, ale trudno na jej podstawie sensownie działać.
W praktyce możesz mieć wynik istotny statystycznie, który ma bardzo małe znaczenie praktyczne. Możesz też mieć wynik nieistotny, ale z efektem wartym uwagi, zwłaszcza przy małej próbie. Dlatego p-value interpretacja powinna być tylko jednym elementem opisu, a nie całym opisem wyniku. Jeśli chcesz uporządkować szerszy sposób zapisu wyników, pomocny będzie też poradnik o tym, jak opisać wyniki statystyczne w pracy dyplomowej krok po kroku.
Co pokazuje effect size i dlaczego warto go raportować
Effect size, czyli wielkość efektu, pokazuje, jak silne jest badane zjawisko. W zależności od analizy może to być na przykład Cohen’s d, eta kwadrat, r, R², Phi albo Cramér’s V. Sama nazwa może brzmieć technicznie, ale idea jest prosta: chodzi o odpowiedź na pytanie, czy wynik jest tylko statystycznie wykrywalny, czy rzeczywiście znaczący.
Jeśli porównujesz dwie grupy, effect size pomaga ocenić, jak duża jest różnica między nimi. Jeśli analizujesz korelację, pokazuje siłę związku między zmiennymi. Jeśli pracujesz na tabelach krzyżowych, pozwala wyjść poza samo stwierdzenie, że zależność jest istotna. To szczególnie ważne w większych próbach, gdzie nawet niewielkie różnice potrafią osiągnąć istotność statystyczną. Przy dobrze opisanym wyniku nie wystarczy więc napisać, że „wynik był istotny”. Trzeba jeszcze pokazać, czy efekt był mały, umiarkowany czy duży.
Jeżeli jesteś dopiero na etapie wyboru metody, warto najpierw sprawdzić, jak dobrać test statystyczny do pracy dyplomowej. Dopiero po właściwym doborze testu ma sens dalsze raportowanie wielkości efektu i interpretowanie wyniku.
Co mówią przedziały ufności
Przedziały ufności pokazują, z jaką precyzją oszacowano wynik. Najczęściej spotkasz zapis typu 95% CI, czyli 95-procentowy przedział ufności. W dużym uproszczeniu: przedział ufności pokazuje zakres wartości, w którym prawdopodobnie mieści się rzeczywisty efekt w populacji. Nie chodzi więc tylko o jedną wartość punktową, ale o pewien zakres niepewności.
To bardzo praktyczne, bo dwa wyniki mogą mieć podobną wartość, ale zupełnie inną precyzję. Wąski przedział ufności sugeruje większą precyzję oszacowania, a bardzo szeroki przedział mówi: „ostrożnie, ten wynik jest dość niepewny”. I właśnie tutaj przedział ufności interpretacja staje się czymś więcej niż dodatkiem do tabeli. Pomaga zobaczyć, czy wynik jest stabilny, czy raczej wymaga ostrożnego komentarza.
Warto też pamiętać, że przedziały ufności świetnie uzupełniają p-value. APA Style – tabele i figury pokazuje, że w raportowaniu wyników ważna jest przejrzystość tabel, estymacji i zakresów niepewności. Z kolei UCLA OARC o pisaniu wyników statystycznych zwraca uwagę, że nie warto ograniczać opisu tylko do ogólnego stwierdzenia „wynik istotny” albo „wynik nieistotny”.
Jak raportować effect size i przedziały ufności w pracy dyplomowej
Dobre raportowanie wyników statystycznych powinno odpowiadać na kilka prostych pytań: co analizowano, jakim testem, jaki był wynik, jaka była wielkość efektu i co oznacza przedział ufności. Nie chodzi o robienie z rozdziału wyników akademickiego labiryntu. Chodzi o to, żeby czytelnik widział pełniejszy obraz wyniku.
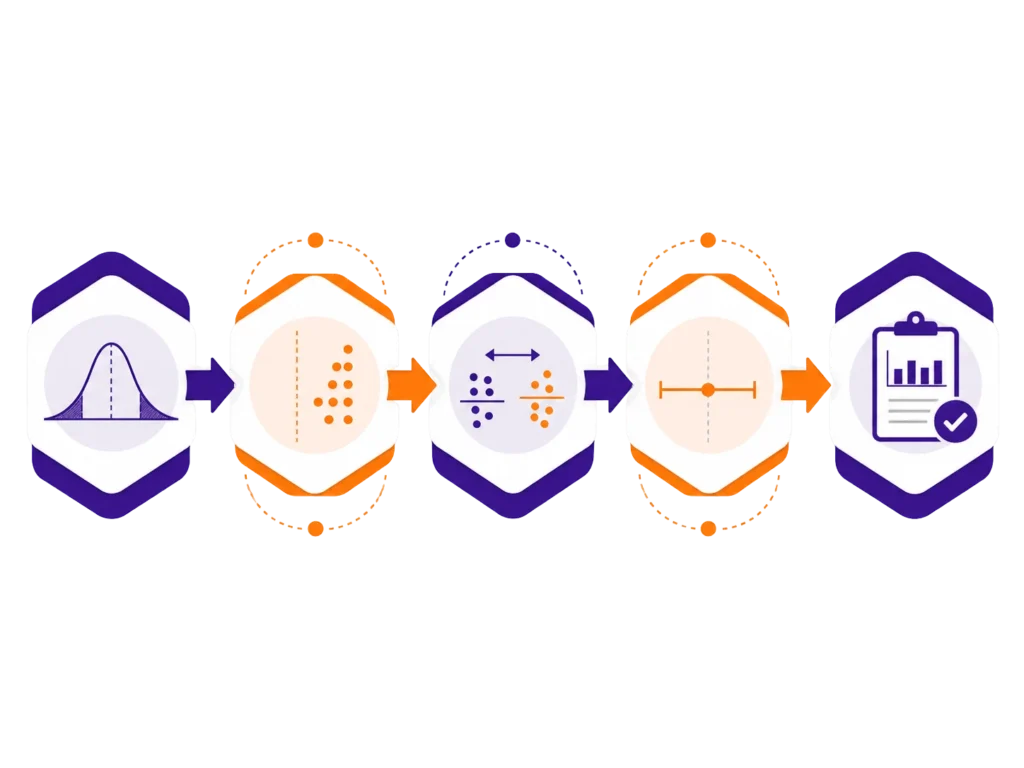
Najlepiej trzymać się prostego schematu:
Taki opis jest znacznie mocniejszy niż samo „p < 0,05”. Pokazuje, że nie tylko kliknięto analizę w programie, ale też zrozumiano, co wynik faktycznie mówi. Jeśli porównujesz dwie grupy i nie wiesz, czy wybrać test t-Studenta czy U Manna-Whitneya, najpierw uporządkuj dobór testu, a dopiero potem przejdź do raportowania efektu. Jeśli analizujesz zależność między zmiennymi, pomocny będzie wpis Pearson czy Spearman, bo rodzaj korelacji również wpływa na sposób opisu wyniku.
Masz wyniki z programu, ale nie wiesz, które liczby powinny trafić do pracy i jak je opisać? Mogę pomóc Ci uporządkować raportowanie wyników: od p-value, przez effect size, aż po przedziały ufności.
Przykład zapisu dla porównania grup
Przykład prostego zapisu może wyglądać tak:
„W celu porównania poziomu stresu między dwiema grupami zastosowano test t-Studenta dla prób niezależnych. Wynik okazał się istotny statystycznie, t(78) = 2,41; p = 0,018. Wielkość efektu była umiarkowana, d = 0,54, co wskazuje, że różnica między grupami miała znaczenie nie tylko statystyczne, ale również interpretacyjne.”
Taki opis jest dużo bardziej użyteczny niż samo podanie p-value. Czytelnik wie, jaki test zastosowano, co wyszło i jak duża była różnica. Oczywiście w konkretnej pracy trzeba dopasować zapis do wyniku, typu testu i wymagań promotora, ale sam schemat jest zdrowy metodologicznie.
Przykład zapisu dla korelacji
Przy korelacji zapis może wyglądać tak:
„Analiza wykazała dodatni związek między samooceną a satysfakcją z życia, r = 0,42; p < 0,001. Siła zależności była umiarkowana, co oznacza, że wyższemu poziomowi samooceny towarzyszył wyższy poziom satysfakcji z życia.”
Jeżeli program podaje przedział ufności dla współczynnika korelacji, warto go dodać. Wtedy opis jest jeszcze pełniejszy, bo pokazuje nie tylko kierunek i siłę związku, ale też precyzję oszacowania. To szczególnie przydatne wtedy, gdy wynik ma być później omawiany w dyskusji albo porównywany z wcześniejszymi badaniami.
Najczęstsze błędy przy raportowaniu wyników
Najczęstszy błąd polega na traktowaniu p-value jak wyroku ostatecznego. Wynik jest istotny, więc „hipoteza potwierdzona” i koniec historii. Niestety to za mało. Statystyka nie działa jak pieczątka w urzędzie, gdzie jedno „zatwierdzono” kończy temat. Wynik trzeba jeszcze zrozumieć.
Drugi błąd to podawanie effect size bez interpretacji. Sama wartość d = 0,25 albo r = 0,31 niewiele powie czytelnikowi, jeśli nie dopiszesz, co to oznacza w kontekście badania. Trzeci błąd to mechaniczne używanie progów bez refleksji. Owszem, są orientacyjne interpretacje małego, średniego i dużego efektu, ale nie powinno się ich traktować jak praw fizyki. W badaniach społecznych i psychologicznych znaczenie wyniku zależy od tematu, skali, próby i praktycznego kontekstu.
Czwarty błąd to pomijanie przedziałów ufności, gdy są dostępne. Jeśli masz możliwość pokazania, jak precyzyjny jest wynik, warto to zrobić. Dzięki temu opis nie zatrzymuje się na jednej liczbie, tylko pokazuje, jak stabilne może być oszacowanie.
Kiedy warto skonsultować opis wyników statystycznych
Warto skonsultować opis wyników wtedy, gdy masz już output z programu, ale nie wiesz, co naprawdę powinno trafić do pracy. To częsty moment blokady: wyniki są policzone, tabele istnieją, ale opis nadal wygląda jak zrzut ekranu przepisany na zdania. Właśnie wtedy dobrze sprawdzić, czy p-value, wielkość efektu i przedziały ufności są opisane spójnie i bez nadinterpretacji.
Pomoc przy wynikach ma sens także wtedy, gdy promotor oczekuje bardziej kompletnego raportowania, a Ty nie masz pewności, które wskaźniki dodać. Nie każdy test wymaga takiego samego opisu, nie każdy effect size pasuje do każdej analizy i nie każdy przedział ufności da się interpretować identycznie. Jeśli chcesz, mogę pomóc uporządkować wyniki, dobrać właściwe wskaźniki i przygotować opis tak, żeby był konkretny, zrozumiały i metodologicznie do obrony. Zobacz usługę analizy statystycznej albo przejdź do kontaktu i podeślij wyniki do wstępnej oceny.
Jeśli masz już output z programu i nie chcesz zgadywać, jak poprawnie opisać wynik, podeślij dane albo fragment analizy. Sprawdzę, co warto zaraportować i jak zapisać wynik tak, żeby był czytelny, konkretny i metodologicznie bezpieczny.





