Regresja liniowa w pracy magisterskiej ma sens wtedy, gdy chcesz sprawdzić, czy jedna zmienna pozwala przewidywać wynik drugiej zmiennej. To nie jest analiza, którą wykonuje się „bo wygląda poważnie” albo dlatego, że korelacja wyszła ładnie i szkoda jej zostawić samej. Regresja odpowiada na trochę inne pytanie: nie tylko czy zmienne są ze sobą powiązane, ale też czy jedna z nich może pełnić rolę predyktora. W praktyce najczęściej pojawia się wtedy, gdy chcesz sprawdzić, czy np. poziom stresu, samoocena, wiek, satysfakcja z życia albo wynik w skali psychologicznej przewiduje inną zmienną.
Kiedy regresja liniowa w pracy magisterskiej ma sens
Regresja liniowa w pracy magisterskiej sprawdza się wtedy, gdy masz zmienną zależną mierzoną liczbowo i chcesz wyjaśnić jej wynik za pomocą jednej lub kilku zmiennych niezależnych. Przykład? Możesz sprawdzić, czy poziom stresu przewiduje jakość snu, czy samoocena przewiduje satysfakcję z życia albo czy liczba godzin nauki przewiduje wynik egzaminu. W takim układzie regresja pozwala przejść od prostego „czy coś jest powiązane” do bardziej konkretnego „czy ta zmienna pomaga przewidywać wynik”.
Nie oznacza to jednak, że regresja jest zawsze najlepszym wyborem. Jeśli porównujesz dwie grupy, prawdopodobnie potrzebujesz raczej testu różnic, a jeśli chcesz tylko sprawdzić związek między dwiema zmiennymi, czasem wystarczy korelacja. Dlatego przed wyborem regresji warto najpierw uporządkować pytanie badawcze i sprawdzić, jak dobrać test statystyczny do pracy dyplomowej. Regresja jest mocnym narzędziem, ale tylko wtedy, gdy odpowiada na właściwe pytanie. Inaczej robi się z niej statystyczny młotek, którym ktoś próbuje naprawić zegarek.
Czym regresja różni się od korelacji
Korelacja pokazuje, czy dwie zmienne są ze sobą powiązane i w jakim kierunku. Regresja idzie krok dalej, bo pozwala sprawdzić, czy jedna zmienna przewiduje drugą. W korelacji zwykle mówisz: „im więcej jednej zmiennej, tym więcej albo mniej drugiej”. W regresji pytasz: „o ile zmienia się wynik zmiennej zależnej, gdy zmienna niezależna wzrasta o jedną jednostkę”.
To rozróżnienie jest ważne, bo wiele osób traktuje regresję jak „bardziej zaawansowaną korelację”, a to uproszczenie potrafi prowadzić na metodologiczne manowce. Jeśli interesuje Cię sam związek między zmiennymi, pomocny może być wpis Pearson czy Spearman. Jeśli jednak chcesz przewidywać wartość jednej zmiennej na podstawie drugiej, regresja może być lepszym wyborem. Nadal jednak trzeba pamiętać o jednej rzeczy: regresja nie dowodzi automatycznie przyczynowości. To, że jedna zmienna przewiduje drugą w modelu, nie oznacza jeszcze, że ją powoduje.
Jak przygotować dane do regresji liniowej
Zanim uruchomisz regresję w SPSS, jamovi, R albo w innym programie, trzeba sprawdzić, czy dane nadają się do takiej analizy. Najpierw upewnij się, że zmienna zależna jest liczbową zmienną ilościową, a zmienne niezależne są poprawnie zakodowane. Jeśli używasz zmiennych kategorialnych, na przykład płci, grupy badanej albo typu terapii, muszą być zakodowane w sposób sensowny dla modelu. Program policzy wszystko, co mu podasz, ale nie ma obowiązku rozumieć, że w arkuszu panuje chaos. Program to nie promotor, nie zapyta z troską: „czy na pewno o to Ci chodziło?”.
Przed regresją warto też sprawdzić braki danych, obserwacje odstające, liniowość zależności i podstawowe założenia regresji liniowej. Bardzo pomocne są tutaj wykresy rozrzutu, analiza reszt i kontrola wartości nietypowych. Jeśli dataset nie jest jeszcze uporządkowany, dobrze zacząć od wpisu o tym, jak oczyścić dane do analizy statystycznej. Przy regresji jakość danych ma szczególne znaczenie, bo pojedyncze wartości odstające potrafią mocno wpłynąć na nachylenie linii regresji i końcowy wynik.
Przed wykonaniem regresji warto sprawdzić szczególnie:
Dobrą praktyką jest też zajrzenie do materiałów Penn State STAT 501 o regresji liniowej, gdzie regresja jest pokazana jako metoda badania zależności między zmienną odpowiedzi i predyktorem. Przy pracy w SPSS przydatne mogą być również materiały UCLA OARC o interpretacji outputu regresji w SPSS, bo pokazują, jak czytać tabelę wynikową zamiast tylko nerwowo szukać kolumny z p-value.
Jak czytać współczynniki regresji liniowej
Największy problem z regresją zwykle zaczyna się nie przy klikaniu analizy, ale przy interpretacji tabeli. W outputcie pojawiają się współczynniki B, beta, błąd standardowy, t, p-value, R², czasem przedziały ufności i nagle człowiek czuje się, jakby otworzył kokpit samolotu zamiast wyników pracy magisterskiej. Spokojnie. Da się to rozłożyć na kilka prostych elementów.
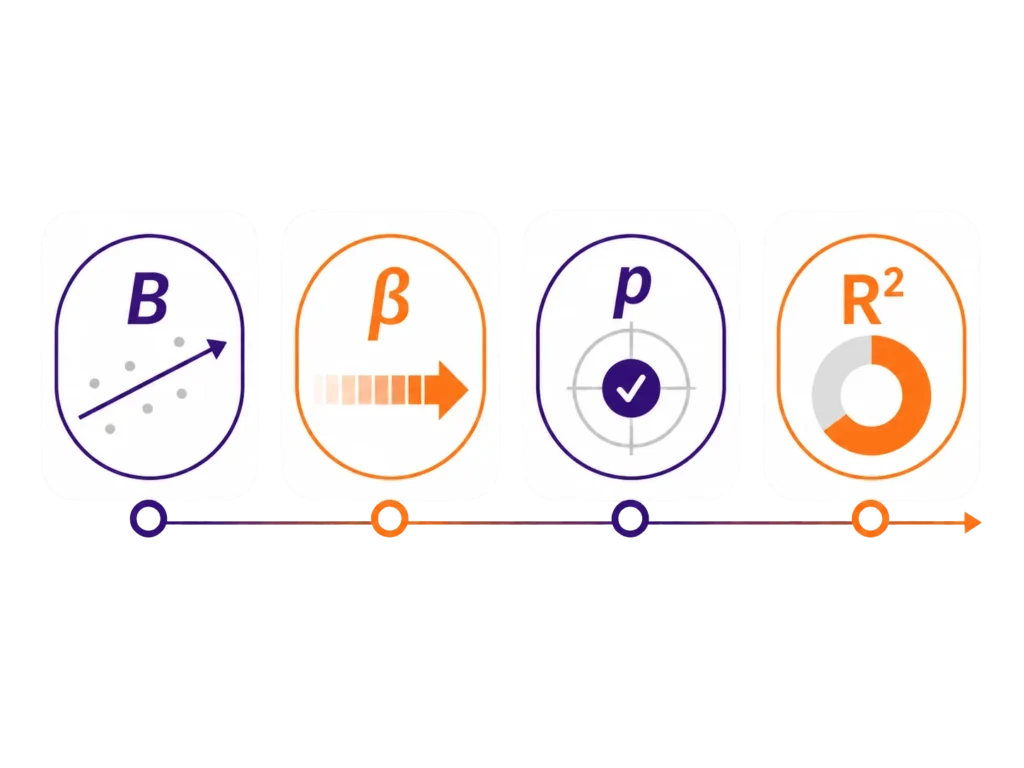
Współczynnik B i beta
Współczynnik B pokazuje, o ile zmieni się przewidywana wartość zmiennej zależnej, gdy predyktor wzrośnie o jedną jednostkę, przy założeniu, że pozostałe zmienne w modelu są kontrolowane. Jeśli B jest dodatnie, wzrost predyktora wiąże się ze wzrostem zmiennej zależnej. Jeśli B jest ujemne, wzrost predyktora wiąże się ze spadkiem zmiennej zależnej. To właśnie tutaj zaczyna się praktyczna regresja liniowa interpretacja współczynników.
Współczynnik beta, czyli standaryzowany współczynnik regresji, pomaga porównywać siłę predyktorów mierzonych na różnych skalach. Jeśli w jednym modelu masz np. wiek, wynik w kwestionariuszu i liczbę godzin nauki, to wartości B mogą być trudne do porównania, bo każda zmienna ma inną jednostkę. Współczynnik beta w regresji ułatwia ocenę, który predyktor ma silniejszy związek ze zmienną zależną. Nie oznacza to jednak, że największa beta zawsze automatycznie „wygrywa interpretację”. Trzeba jeszcze patrzeć na sens teoretyczny, p-value, przedziały ufności i cały kontekst badania.
p-value, przedział ufności i R²
P-value informuje, czy dany predyktor jest istotny statystycznie w modelu. Jeśli p-value jest poniżej przyjętego poziomu istotności, zwykle mówi się, że predyktor istotnie przewiduje zmienną zależną. Ale samo p-value to za mało. W dobrze opisanej regresji warto pokazać także kierunek zależności, wielkość współczynnika i jeśli jest dostępny, przedział ufności.
R² pokazuje, jaka część zmienności zmiennej zależnej jest wyjaśniana przez model. To ważna informacja, bo model może mieć istotne predyktory, ale wyjaśniać niewielką część wyniku. R kwadrat interpretacja powinna więc być ostrożna. Jeśli R² = 0,20, możesz napisać, że model wyjaśnia 20% zmienności zmiennej zależnej. Nie oznacza to jednak, że „badanie wyjaśniło 20% człowieka”, bo brzmi to jak coś między statystyką a cyberpunkową dystopią. Chodzi o zmienność konkretnej zmiennej w konkretnym modelu.
Jeśli chcesz raportować wyniki dokładniej, zobacz też wpis effect size i przedziały ufności, bo regresja bardzo dobrze łączy się z myśleniem szerszym niż samo „istotne / nieistotne”.
Jak opisać regresję liniową w pracy magisterskiej
Opis regresji powinien być prosty, ale kompletny. Najpierw napisz, jaki był cel analizy, czyli co próbujesz przewidzieć i za pomocą jakich zmiennych. Następnie podaj informację o dopasowaniu modelu, na przykład R², oraz wskaż, które predyktory okazały się istotne. Dopiero potem przejdź do interpretacji współczynników.
Przykład prostego opisu może wyglądać tak:
„W celu sprawdzenia, czy poziom stresu przewiduje jakość snu, przeprowadzono analizę regresji liniowej. Model okazał się istotny statystycznie i wyjaśniał 18% zmienności jakości snu. Poziom stresu był istotnym ujemnym predyktorem jakości snu, co oznacza, że wyższy poziom stresu wiązał się z niższą jakością snu.”
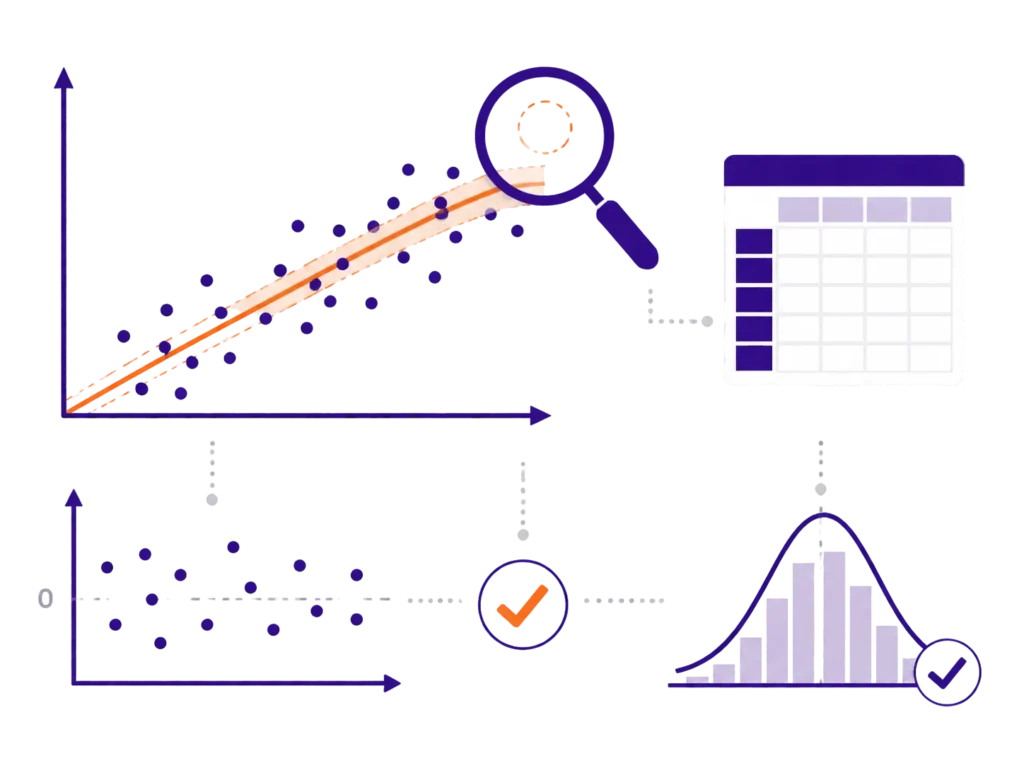
Taki opis jest dużo lepszy niż samo przepisanie tabeli z programu. Czytelnik wie, co analizowano, jaki był kierunek zależności i jak rozumieć wynik. Jeśli masz już output z programu, ale nie wiesz, które liczby powinny trafić do pracy, zobacz poradnik jak opisać wyniki statystyczne w pracy dyplomowej krok po kroku. To dobry kolejny krok, bo sama tabela regresji to jeszcze nie opis wyników, tylko materiał do opisu.
Masz wynik regresji, ale nie wiesz, czy dobrze czytasz B, beta, p-value i R²? Mogę pomóc Ci uporządkować analizę, sprawdzić model i przygotować opis wyników w formie nadającej się do pracy. Zobacz usługę analizy statystycznej albo przejdź do kontaktu i podeślij wyniki do wstępnej oceny.
Kiedy warto skonsultować regresję przed oddaniem pracy
Regresję warto skonsultować szczególnie wtedy, gdy masz więcej niż jeden predyktor, zmienne kategorialne, podejrzenie outlierów albo niejasne wyniki. W prostym modelu z jedną zmienną niezależną interpretacja bywa jeszcze dość przejrzysta. W regresji wielorakiej łatwo jednak pomylić wpływ pojedynczego predyktora z działaniem całego modelu. To klasyczny moment, w którym wynik wygląda elegancko, ale jedno źle użyte zdanie potrafi osłabić cały opis.
Konsultacja ma sens także wtedy, gdy promotor oczekuje konkretnego sposobu raportowania, a Ty nie masz pewności, czy opis jest wystarczająco precyzyjny. Czasem problemem nie jest sama analiza, tylko to, że wynik został opisany zbyt mocno, zbyt przyczynowo albo zbyt ogólnie. Regresja jest bardzo użyteczna, ale wymaga ostrożnego języka. Lepiej napisać, że zmienna „przewiduje wynik” albo „jest istotnym predyktorem”, niż bez podstaw twierdzić, że „powoduje zmianę”.
Regresja liniowa w pracy magisterskiej może być bardzo dobrym wyborem, jeśli Twoje pytanie badawcze dotyczy przewidywania wyniku albo wyjaśniania zmienności zmiennej zależnej. Trzeba jednak poprawnie przygotować dane, sprawdzić założenia, zrozumieć współczynniki i opisać wynik bez nadinterpretacji. Jeśli masz wynik regresji i chcesz upewnić się, że opis jest metodologicznie bezpieczny, podeślij tabelę albo opisz układ badania. Sprawdzę, co oznaczają współczynniki i jak zapisać wynik tak, żeby nie brzmiał jak tłumaczenie z języka programu na język chaosu.





