Jeśli zastanawiasz się, jak oczyścić dane do analizy statystycznej, to dobrze zacząć od jednej prostej myśli: bardzo wiele problemów z analizą nie zaczyna się przy wyborze testu, tylko dużo wcześniej. Dataset może wyglądać niewinnie, ale kilka braków danych, źle zakodowane odpowiedzi albo kilka obserwacji odstających potrafi skutecznie wywrócić wynik do góry nogami. I wtedy człowiek ma wrażenie, że statystyka „nie działa”, choć tak naprawdę problem leży w materiale wejściowym. Dobra analiza zaczyna się nie od klikania testów, tylko od ogarnięcia danych.
Dlaczego czyszczenie danych decyduje o jakości analizy
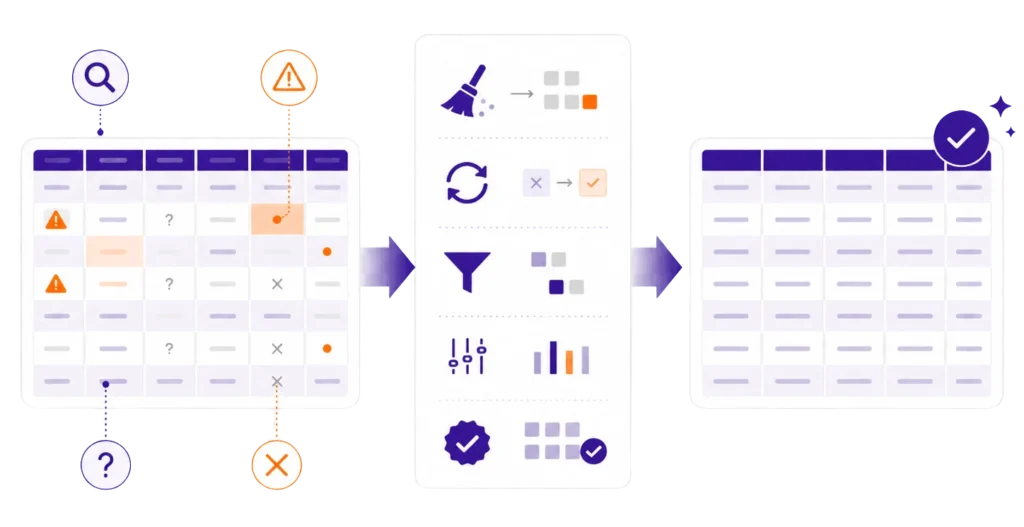
Czyszczenie danych to nie jest kosmetyka ani etap dla perfekcjonistów. To moment, w którym sprawdzasz, czy analizujesz realny materiał badawczy, czy raczej mieszankę poprawnych obserwacji, pustych pól, literówek i niespodzianek z arkusza. W praktyce nawet dobrze dobrany test nie uratuje sytuacji, jeśli dane wejściowe są niespójne albo błędnie zakodowane. Właśnie dlatego przygotowanie danych do analizy jest bardziej fundamentem niż dodatkiem. Najpierw porządek, potem statystyka.
Od czego zacząć, gdy chcesz oczyścić dane do analizy statystycznej
Najlepszy start to nie polowanie na zaawansowane procedury, tylko zwykły przegląd datasetu. Sprawdź, jakie masz zmienne, jak zapisano odpowiedzi, czy nie ma pustych kolumn, czy wszystkie wartości mieszczą się w logicznym zakresie i czy nazwy zmiennych są czytelne. To etap mało widowiskowy, ale bardzo praktyczny, bo pozwala szybko zauważyć rzeczy, które później rozwalają analizę od środka. Jeśli chcesz wiedzieć, jak oczyścić dane do analizy statystycznej, to właśnie tutaj zaczyna się cała robota, a nie przy pierwszym kliknięciu w SPSS czy jamovi.
Jak sprawdzić braki danych w analizie statystycznej
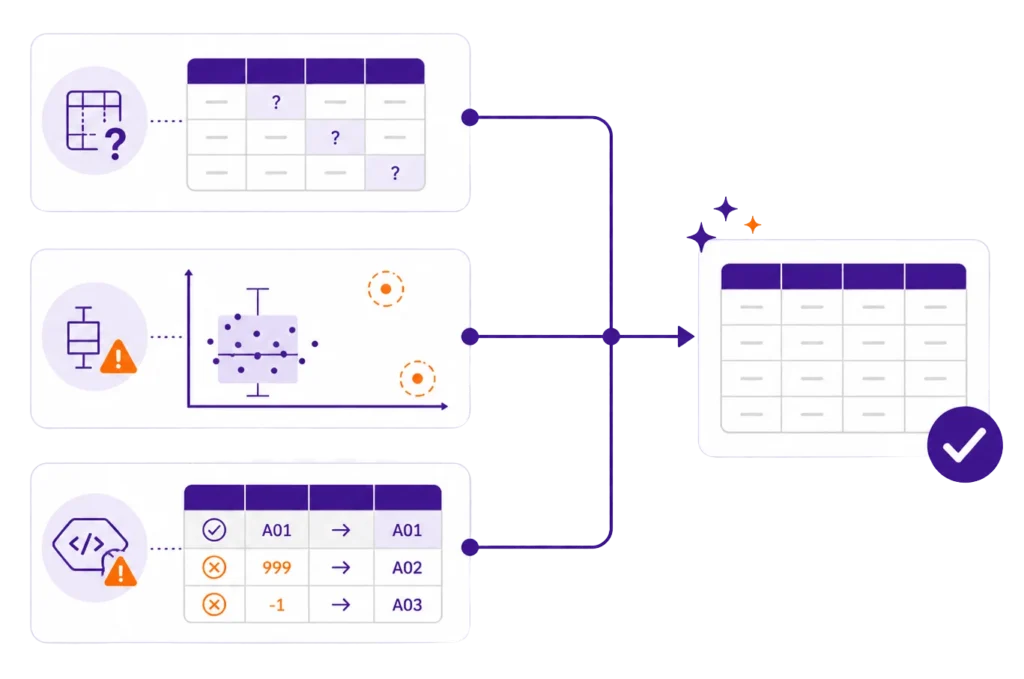
Braki danych w analizie statystycznej trzeba sprawdzić zanim przejdziesz do testów, bo różne procedury różnie sobie z nimi radzą. Najpierw warto sprawdzić liczbę braków w zmiennych i wzorce braków danych między obserwacjami. To ważne, bo problemem nie jest tylko sam brak odpowiedzi, ale też jego wzorzec: czasem braki są rozproszone, a czasem skupiają się w jednym fragmencie danych i zaczynają realnie zniekształcać analizę. UCLA OARC zwraca uwagę, że sensownie jest sprawdzić zarówno liczbę braków w zmiennych, jak i wzorce braków między obserwacjami, bo część procedur może działać tylko na kompletnych przypadkach.
Kiedy brak danych to drobiazg, a kiedy realny problem
Pojedyncze braki nie muszą oznaczać katastrofy. Problem zaczyna się wtedy, gdy braków jest dużo, dotyczą kluczowych zmiennych albo wycinają z analizy sporą część przypadków. UCLA OARC pokazuje też, że część programów statystycznych domyślnie pomija brakujące wartości w obliczeniach, więc jeśli nie sprawdzisz tego wcześniej, możesz analizować znacznie mniejszą próbę, niż zakładasz. To właśnie dlatego braki danych w analizie statystycznej trzeba potraktować jako element metodologii, a nie techniczny drobiazg.
Jak rozpoznać outliery w danych i nie usuwać ich na ślepo
Outliery w danych to temat, przy którym bardzo łatwo przesadzić w obie strony. Jedni ignorują je całkowicie, drudzy usuwają z zapałem, jakby porządkowali szufladę z kablami. Przy pracy z obserwacjami odstającymi warto oprzeć się na sensownym podejściu do detekcji outlierów, a nie usuwać ich automatycznie. NIST podkreśla, że outlier może wskazywać zarówno na zły zapis danych, jak i na coś realnie interesującego, dlatego nie powinno się go usuwać automatycznie tylko dlatego, że „psuje wykres”. Masz już dane, ale nie wiesz, czy dataset jest poprawnie przygotowany do analizy? Mogę sprawdzić braki danych, outliery, błędne kody i podpowiedzieć, co poprawić jeszcze przed wyborem testu.
Nie każdy outlier jest błędem
Najpierw trzeba zadać sobie pytanie, skąd ten wynik się wziął. Jeśli wartość jest niemożliwa logicznie, na przykład wiek 444 lata albo wynik poza zakresem skali, to problem najpewniej leży w danych. Jeśli jednak obserwacja jest nietypowa, ale możliwa, to warto ją oznaczyć i sprawdzić jej wpływ na wynik zamiast od razu wyrzucać. NIST rozróżnia samo oznaczenie potencjalnego outliera od decyzji, co z nim zrobić dalej, i właśnie to jest zdrowe podejście: najpierw identyfikacja, potem interpretacja, a dopiero na końcu decyzja.
Jak wyłapać błędne kody w bazie danych i niespójne odpowiedzi
Błędne kody w bazie danych są mniej efektowne niż outliery, ale w praktyce równie niebezpieczne. To właśnie tutaj pojawiają się klasyki: raz płeć zakodowana jako 1 i 2, a raz jako K i M; raz brak odpowiedzi zapisany jako puste pole, a raz jako 999; raz skala od 1 do 5, a raz od 0 do 4. Program statystyczny nie domyśli się, co autor miał na myśli. Jeśli w bazie panuje chaos, analiza będzie tylko elegancko policzonym chaosem.
W tym miejscu warto przejrzeć zakresy odpowiedzi dla każdej zmiennej i sprawdzić, czy nie pojawiają się wartości spoza skali, literówki albo mieszanie formatu liczbowego z tekstowym. Bardzo pomaga też szybka tabela częstości dla zmiennych kategorycznych i podstawowy opis statystyczny dla zmiennych ilościowych. To prosty sposób, żeby złapać problemy zanim wejdą do wyników i zaczną udawać prawdziwe zjawiska.
Co sprawdzić przed przejściem do testów i opisu wyników
Na końcu dobrze zrobić jeszcze jedną krótką kontrolę: czy dataset jest spójny, czy typy zmiennych są jasne, czy wiadomo, które wartości są brakami, które obserwacje są odstające i czy wszystkie kody mają sens. Dopiero wtedy przechodzisz do etapu, w którym trzeba zdecydować, jak dobrać test statystyczny do pracy dyplomowej. To właśnie ten moment odróżnia analizę uporządkowaną od analizy robionej „na czuja”. Jeśli dane są czyste, reszta pracy staje się po prostu dużo łatwiejsza. Jeśli w kolejnym kroku chcesz ocenić założenia testów, sprawdź też, jak sprawdzić normalność rozkładu i co z tego wynika.
Jeśli chcesz wiedzieć, jak oczyścić dane do analizy statystycznej, nie zaczynaj od losowego wyboru testu. Najpierw sprawdź braki danych w analizie statystycznej, potem oceń outliery w danych, a na końcu wyłap błędne kody w bazie danych i niespójne odpowiedzi. To właśnie ten etap często decyduje o tym, czy analiza będzie metodologicznie do obrony, czy tylko będzie wyglądała dobrze na pierwszy rzut oka. Jeżeli masz dataset i nie wiesz, czy nadaje się już do analizy, mogę pomóc Ci go uporządkować, sprawdzić i wskazać, od czego najlepiej zacząć. Jeśli Twój plik wygląda bardziej jak pole minowe niż gotowy dataset, nie musisz zgadywać, co poprawić. Podeślij dane albo opisz układ badania, a sprawdzę, co wymaga oczyszczenia i jak bezpiecznie przygotować materiał do dalszej analizy.





